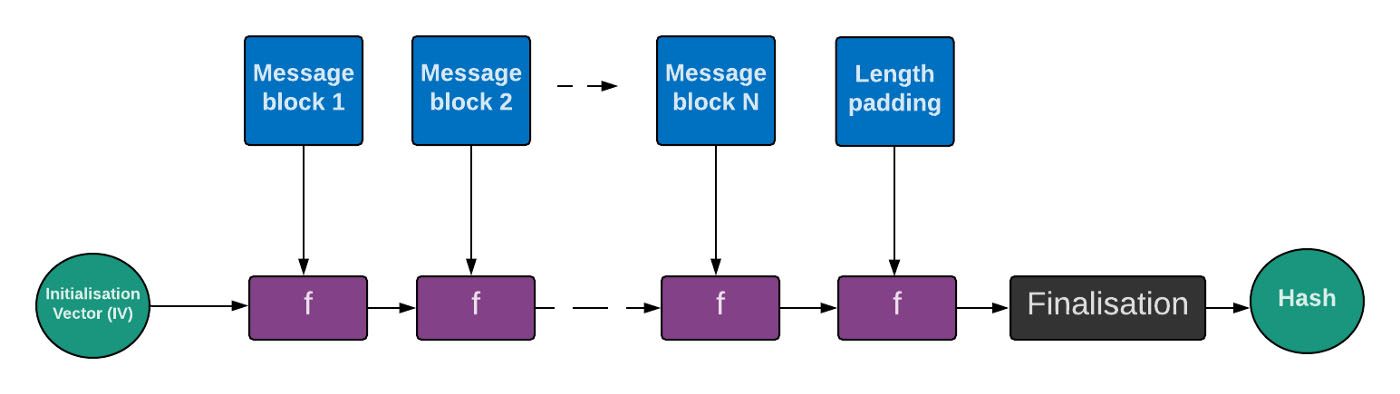
Symmetric and Asymmetric Encryption

What is Encryption and Cryptographic Keys? Encryption is actually an age-old practice dating back to the times of the famous Roman king Caesar, who encrypted his messages using a Caesar cipher. The practice can be viewed as a transformation of information whereby the sender uses plain text, which is then encoded into cipher text to ensure that no eavesdropper interferes with the original plain text. On receiving the encoded message, the intended receiver decrypts it to obtain the original plain text message. Once the transaction data encrypted then it can only be decrypted using the appropriate keys, its called a “Cryptographic keys“. A cryptographic key is a password which is used to encrypt and decrypt information. There are two types of cryptographic keys. They are known as symmetric key and asymmetric key cryptography: symmetric and asymmetric encryption. What is Symmetric Encryption? Symmetric Encryption also called Secret Key Cryptography, it employs the same secret key...