Optimizations of Gradient Descent

Introduction
Gradient Descent is one of the most popular technique to optimize machine learning algorithm. We've already discussed Gradient Descent in the past in Gradient descent with Python article, and gave some intuitions toward it's behaviour. We've also made an overview about choosing learning rate hyper-parameter for the algorithm in hyperparameter optimization article. So by now, you should have a fair understanding of how it works. Today we'll discuss different ways to optimize the performance of the algorithm itself.
Gradient Descent Variants
We've already three variants of the Gradient Descent in Gradient Descent with Python article: Batch Gradient Descent, Stochastic Gradient Descent and Mini-Batch Gradient Descent. What we haven't discussed was problems arising when using these techniques. Choosing a proper learning rate is difficult. A too small learning rate leads to tremendously slow convergence, while a very large learning rate that can cause the loss function to fluctuate around the minimum or even to diverge. Additionally, in all these variants of Gradient Descent the same learning rate applies to all parameter updates. However when the data is sparse with features having different frequencies, it would be better to perform a larger update for rarely occurring features.
Momentum
Gradient Descent struggles navigating ravines, areas where the surface curves much more steeply in one dimension than in another. Once fallen into ravine, Gradient Descent oscillates across the slopes of the ravine, without making much progress towards the local optimum. Momentum technique accelerates Gradient Descent in the relevant direction and lessens oscillations. In the illustrations below, the left one is vanilla Gradient Descent and the right is Gradient Descent with Momentum.

When Momentum technique is applied, the fraction of the update vector of the past time step is added to the current update vector:
The momentum parameter is usually set to 0.9
The idea behind using momentum accelerating speed of the ball as it rolls down the hill, until it reaches its terminal velocity if there is air resistance, that is our parameter . Similarly the momentum increases updates for dimensions whose gradients point in the same directions and reduces updates for dimensions whose gradients change directions gaining faster convergence while reducing oscillation.
Nesterov
The standard momentum method first computes the gradient at the current location and then takes a big jump in the direction of the updated accumulated gradient. The Nesterov accelerated gradient (NAG) looks ahead by calculating the gradient not by our current parameters but by approximating future position of our parameters. In the following illustration, instead of evaluating gradient at the current position (red circle), we know that our momentum is about to carry us to the tip of the green arrow. With Nesterov momentum we therefore instead evaluate the gradient at this "looked-ahead" position.
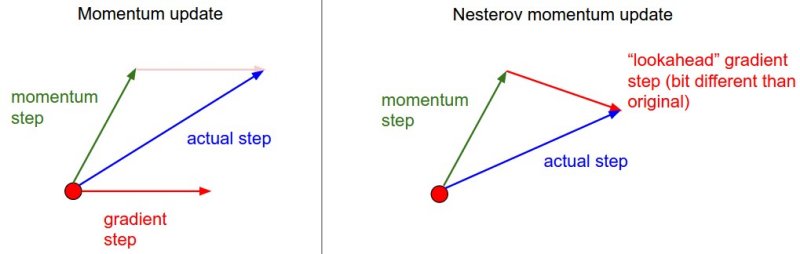
The formula for Nesterov accelerated gradient is as following with momentum parameter set to 0.9:
It enjoys stronger theoretical converge guarantees for convex functions and in practice it also consistently works slightly better than standard momentum.
Adagrad
All previous approaches we’ve discussed so far manipulated the learning rate globally and equally for all parameters. Adagrad is a well-suited algorithm for dealing with sparse data - it edits the learning rate to the parameters, performing larger updates for infrequent and smaller updates for frequent parameters. Adagrad uses a different learning rate for every parameter at each step, and not an update for all parameters at once and given by:
where is an element-wise multiplication, is a smoothing term that avoids division by zero (usually on the order of 1e−8), is a diagonal matrix of sum of the squares of the past gradients -
One of Adagrad's main benefits is that it eliminates the need to manually tune the learning rate. Most implementations use a default value of 0.01 and leave it at that.
Adadelta
Adadelta is an improvement over Adagrad which reduces its aggressiveness and monotonically decreasing learning rate. Instead of accumulating all past squared gradients, Adadelta restricts the window of accumulated past gradients to some fixed size .With Adadelta, we do not even need to set a default learning rate.
RMSprop
RMSprop also tries to overcome the diminishing learning rates of Adagrad and works similarly to Adadelta as following:
where E is a running average. RMSprop as well divides the learning rate by an exponentially decaying average of squared gradients. Momentum rate is usually set to 0.9, while a good default value for the learning rate is 0.001.
The following two animations provide some intuitions towards the optimization behaviour of the presented optimization algorithms on loss surface contours and saddle point:


It's clearly seen how standard SGD legs behind anyone else.
Conclusions
There is no right answer for choosing the correct optimization algorithm as SGD still holds the crown, while the others attempt to decrease learning rate dramatically sometimes sacrificing performance. In fact many papers use vanilla SGD without momentum. However, if you care about fast convergence you should choose one of the adaptive learning rate methods.



Comments
Post a Comment